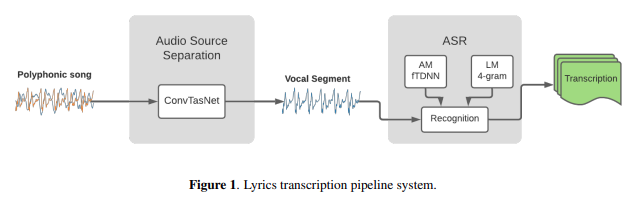
Overview of the ICASSP 2026 Cadenza Challenge: Predicting Lyric Intelligibility
Gerardo Roa-Dabike, Jon P. Barker, Trevor J. Cox, Michael A. Akeroyd, Scott Bannister, Bruno Fazenda, Jennifer Firth, Simone Graetzer, Alinka Greasley, Rebecca R. Vos, and William M. Whitmer
In ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026
@inproceedings{11463231,author={Roa-Dabike, Gerardo and Barker, Jon P. and Cox, Trevor J. and Akeroyd, Michael A. and Bannister, Scott and Fazenda, Bruno and Firth, Jennifer and Graetzer, Simone and Greasley, Alinka and Vos, Rebecca R. and Whitmer, William M.},booktitle={ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},title={Overview of the ICASSP 2026 Cadenza Challenge: Predicting Lyric Intelligibility},year={2026},volume={},number={},pages={21757-21759},keywords={Internet;Protocols;Communication systems;Computer networks;HTTP;Codecs;Over-the-top media services;Streaming media;Machine learning;Artificial intelligence;hearing loss;machine learning;intelligibility;lyrics;music},doi={10.1109/ICASSP55912.2026.11463231},}
Data Paper
The Cadenza lyric intelligibility prediction (CLIP) dataset
Gerardo Roa-Dabike, Trevor J. Cox, Jon P. Barker, Bruno M. Fazenda, Simone Graetzer, Rebecca R. Vos, Michael A. Akeroyd, Jennifer Firth, William M. Whitmer, Scott Bannister, and Alinka Greasley
@article{ROADABIKE2026112466,title={The Cadenza lyric intelligibility prediction (CLIP) dataset},journal={Data in Brief},volume={65},pages={112466},year={2026},issn={2352-3409},doi={https://doi.org/10.1016/j.dib.2026.112466},url={https://www.sciencedirect.com/science/article/pii/S2352340926000193},author={Roa-Dabike, Gerardo and Cox, Trevor J. and Barker, Jon P. and Fazenda, Bruno M. and Graetzer, Simone and Vos, Rebecca R. and Akeroyd, Michael A. and Firth, Jennifer and Whitmer, William M. and Bannister, Scott and Greasley, Alinka},}
2025
Data Paper
The First Cadenza Challenges: Using Machine Learning Competitions to Improve Music for Listeners With a Hearing Loss
Gerardo Roa-Dabike, Michael A. Akeroyd, Scott Bannister, Jon P. Barker, Trevor J. Cox, Bruno Fazenda, Jennifer Firth, Simone Graetzer, Alinka Greasley, Rebecca R. Vos, and William M. Whitmer
@article{roadabike2025_ojsp,author={Roa-Dabike, Gerardo and Akeroyd, Michael A. and Bannister, Scott and Barker, Jon P. and Cox, Trevor J. and Fazenda, Bruno and Firth, Jennifer and Graetzer, Simone and Greasley, Alinka and Vos, Rebecca R. and Whitmer, William M.},journal={IEEE Open Journal of Signal Processing},title={The First Cadenza Challenges: Using Machine Learning Competitions to Improve Music for Listeners With a Hearing Loss},year={2025},volume={6},number={},pages={722-734},doi={10.1109/OJSP.2025.3578299},}
2024
Conference
The ICASSP SP Cadenza Challenge: Music Demixing/Remixing for Hearing Aids
Gerardo Roa-Dabike, Michael A. Akeroyd, Scott Bannister, Jon Barker, Trevor J. Cox, Bruno Fazenda, Jennifer Firth, Simone Graetzer, Alinka Greasley, Rebecca R. Vos, and William M. Whitmer
In 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), 2024
@inproceedings{roadabike2024_icassp,author={Roa-Dabike, Gerardo and Akeroyd, Michael A. and Bannister, Scott and Barker, Jon and Cox, Trevor J. and Fazenda, Bruno and Firth, Jennifer and Graetzer, Simone and Greasley, Alinka and Vos, Rebecca R. and Whitmer, William M.},booktitle={2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW)},title={The ICASSP SP Cadenza Challenge: Music Demixing/Remixing for Hearing Aids},year={2024},volume={},number={},pages={93-94},doi={10.1109/ICASSPW62465.2024.10626340},}
Data Paper
The Cadenza Woodwind dataset: Synthesised quartets for music information retrieval and machine learning
Gerardo Roa-Dabike, Trevor J. Cox, Alex J. Miller, Bruno M. Fazenda, Simone Graetzer, Rebecca R. Vos, Michael A. Akeroyd, Jennifer Firth, William M. Whitmer, Scott Bannister, Alinka Greasley, and Jon P. Barker
@article{roadabike2024_dib,title={The Cadenza Woodwind dataset: Synthesised quartets for music information retrieval and machine learning},journal={Data in Brief},volume={57},pages={111199},year={2024},issn={2352-3409},doi={https://doi.org/10.1016/j.dib.2024.111199},url={https://www.sciencedirect.com/science/article/pii/S2352340924011612},author={Roa-Dabike, Gerardo and Cox, Trevor J. and Miller, Alex J. and Fazenda, Bruno M. and Graetzer, Simone and Vos, Rebecca R. and Akeroyd, Michael A. and Firth, Jennifer and Whitmer, William M. and Bannister, Scott and Greasley, Alinka and Barker, Jon P.},}
2021
Conference
The use of Voice Source Features for Sung Speech Recognition
@inproceedings{roadabike2021_icassp,author={Roa-Dabike, Gerardo and Barker, Jon P.},booktitle={2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},title={The use of Voice Source Features for Sung Speech Recognition},year={2021},volume={},number={},pages={6513-6517},doi={10.1109/ICASSP39728.2021.9414950},}
2020
Workshop
The Sheffield University System for the MIREX 2020: Lyrics Transcription Task
@inproceedings{inproceedings,author={Roa-Dabike, Gerardo and Barker, Jon},year={2020},month=nov,pages={},booktitle={Mirex 2020},title={The Sheffield University System for the MIREX 2020: Lyrics Transcription Task},}
2019
Conference
Automatic Lyric Transcription from Karaoke Vocal Tracks: Resources and a Baseline System
@inproceedings{roadabike2019_interspeech,title={Automatic Lyric Transcription from Karaoke Vocal Tracks: Resources and a Baseline System},author={Roa-Dabike, Gerardo and Barker, Jon P.},year={2019},booktitle={Interspeech 2019},pages={579--583},doi={10.21437/Interspeech.2019-2378},issn={2958-1796},}